关于你可能知道的 slice
slice 实现原理
slice 是一段底层数组的描述。
在 golang spec 是这么说的:
A slice is a descriptor for a contiguous segment of an underlying array and provides access to a numbered sequence of elements from that array. A slice type denotes the set of all slices of arrays of its element type. The number of elements is called the length of the slice and is never negative. The value of an uninitialized slice is
nil.切片是底层数组的连续段的描述符,提供对该数组中编号的元素序列的访问。切片类型表示其元素类型的数组的所有切片的集合。元素的数量称为切片的长度,并且永远不会为负。未初始化切片的值为
nil。
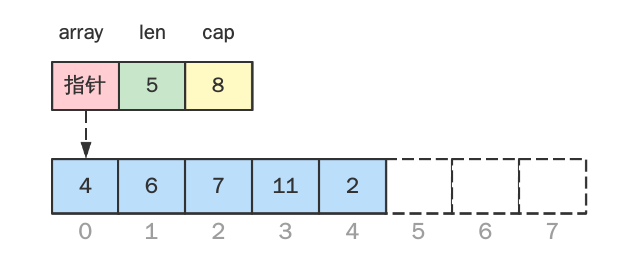
slice 结构
在源码包中 src/runtime/slice.go:slice 对 Slice 定义如下:
| |
通过这个结构体可以更清晰看出,切片是基于一个底层数组的(即 array 字段,其为一个指针,指向一个数组),并且带有两个字段:长度 len 和 容量 cap。
容量,指的是切片的底层数组的元素最大个数。
长度,指的是切片的底层数组的元素目前个数。
创建切片共有 3 种方式:
通过字面量直接创建
基于已有 数组/slice 创建
通过 make() 创建
1 2 3 4 5arr := [8]int{1, 2, 3, 4, 5, 6, 7, 8} s1 := []int{11, 22, 33} // 1. 通过字面量直接创建 s2 := arr[2:6] // 2. 通过下标基于数组或切片创建 s3 := make([]int, 10, 20) // 3. 通过关键字 make 创建
[:] re-slice
[:] 语法在 golang spec 称为 Slice Expression,也有称作 re-slice,是 golang 中很常用的一种获得切片的方法。但在使用时有一些地方需要注意。
[:] 语法有两种基本形式:
[low : high][low : high : max]
第一种基本形式中,low 和 high 都允许使用字面常量或变量,都允许忽略不写,所以有以下几种形式:
[2:5]、[2:]、[:5]、[:]
第二种基本形式中,low、high、max 都允许使用字面常量或变量,但只允许 low 忽略不写,所以只有 2 种形式:
[2:5:6]、[:5:6]
在忽略不写的情况下:
low的默认值为
0,即基础数组的第一个元素开始算起high的默认值为
len(基础数组/切片),即基础数组/切片的最后一个max 的默认值为
len(底层数组),即底层数组的最后一个元素(包含最后一个元素)
举个栗子:
| |
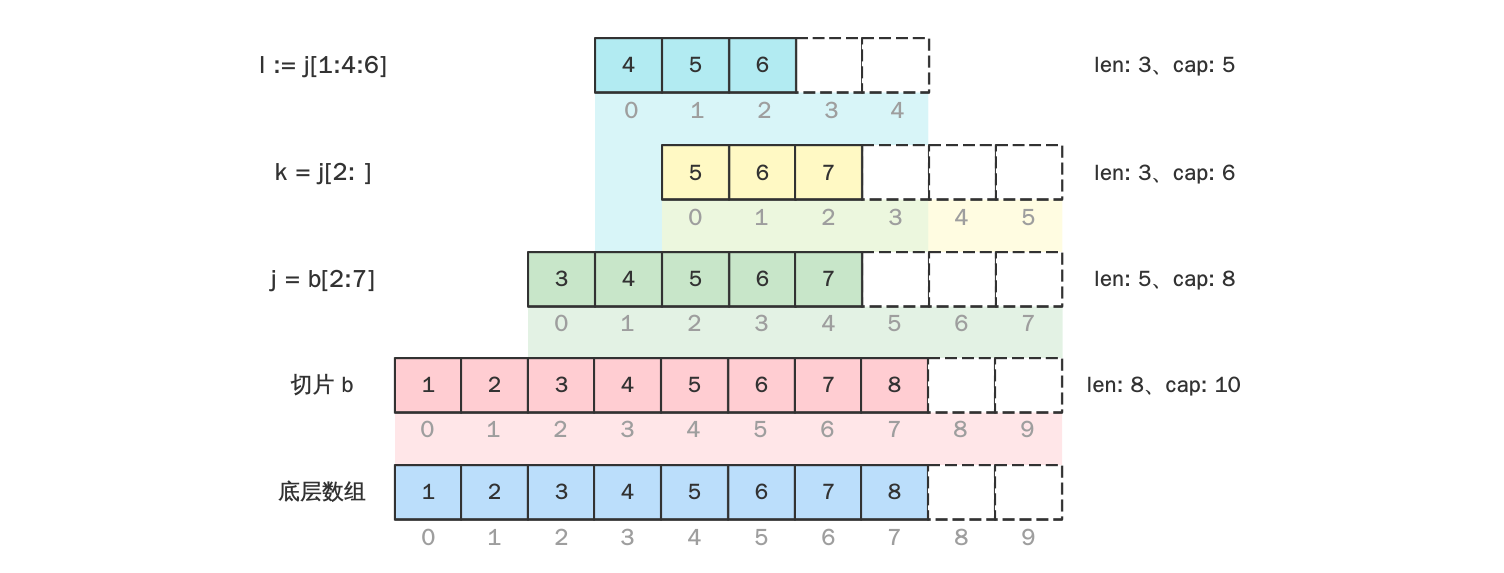
此外 low、high、max 的默认值也有一些要求,但概括起来就是: $$ 0 \le low \le len(s) \le high \le max \le cap(s) $$ 即:low 不能超过 high、high 不能超过 max、max 不能超过 cap(s);反之,max 不能小于 high、high 不能小于 low、low 不能小于 0。
- low 的取值在
[0, high] - high 的取值在
[low, max] - max 的取值在
[high, cap(s)]
扩容策略
Slice 是基于底层数组的一种动态数组,相对于长度固定的数组,Slice 更灵活,且体现在:当底层数组容量不足时,Slice 会自动扩容。既然会自动扩容,那么就一定有扩容策略。
扩容关注点:容量
扩容时机:len(s) == cap(s)
扩容触发场景:len(s) == cap(s) 时继续使用 append() 追加元素
扩容策略:
扩容后能容纳要追加的元素:
if oldCap < 1024 { newCap = oldCap * 2}if oldCap >= 1024 { newCap = oldCap * 1.25}
扩容后不能容纳要追加的元素:
- newCap = 预估的容量
复制问题
在复制 Slice 时,如果仅仅使用等于号 s1 = s2,这样只是拷贝了一个地址。
要实现完全的复制,需要使用 golang 提供的 copy() 函数。
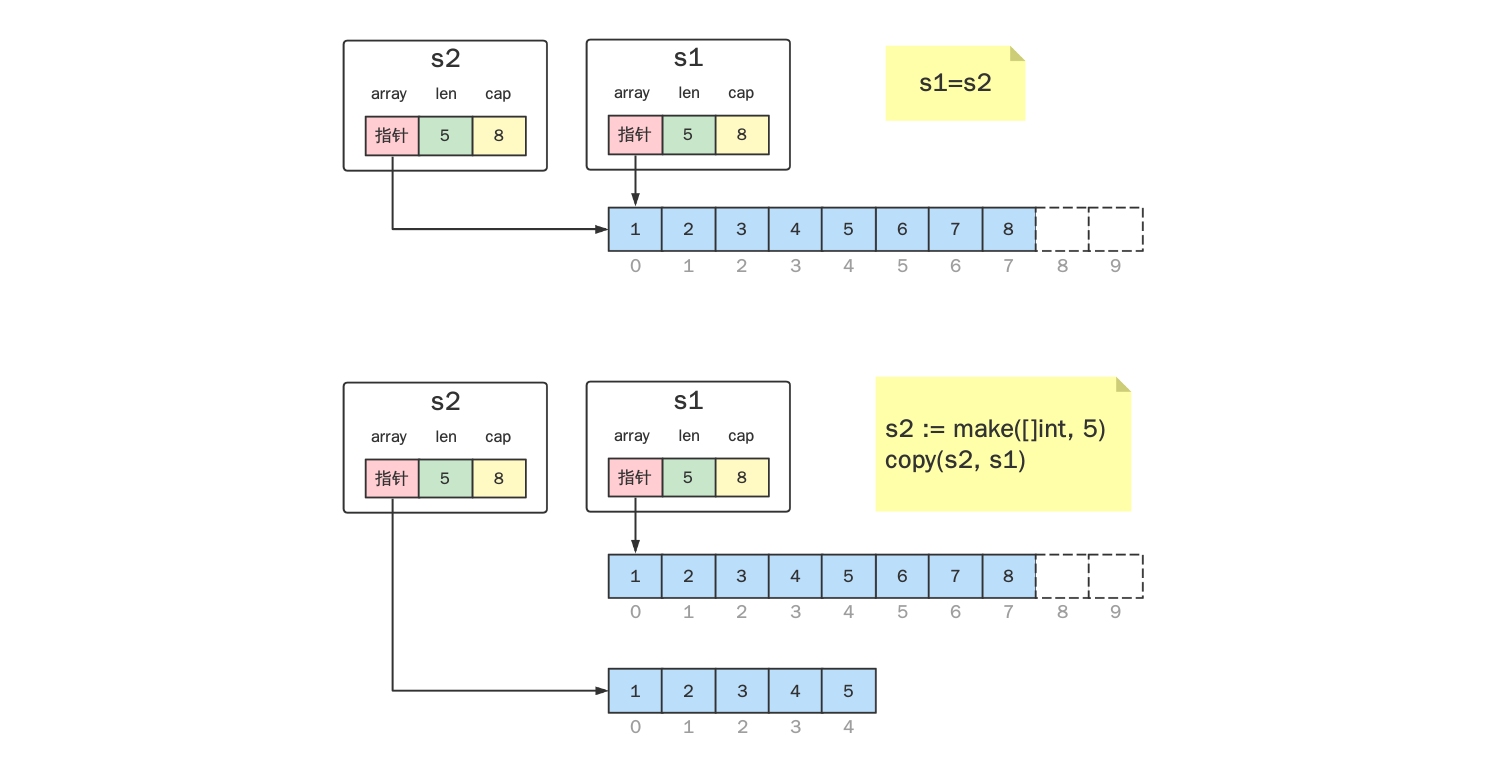
使用 copy() 拷贝时,会将源切片的元素逐个拷贝到目的切片指向的数组中,拷贝的数量取两个切片长度的最小值。例如上图中,s1 长度为 8,s2 长度为 5,则共拷贝 5 个元素,即 copy() 不会发生扩容。
注意,
copy()是覆盖行为。原有数据将会被覆盖。
比较问题
在 Slice 的比较中,因为 Slice 不是可比较类型,直接用恒等号 == 比较是无法通过编译的,如果取地址比较也是行不通的,因为 Slice 是结构体,取地址比较的是两个结构体,自然是 false。
| |
所以,Slice 比较肯定不是那么肤浅的。
Slice 的比较在网上盛传的有两种:使用 reflect.DeepEqual() 和 手写比较函数。
因为 reflect.DeepEqual() 效率较低,所以才有手写比较函数。下面简单展示下 DeepEqual(),然后讲解手写比较函数。
reflect.DeepEqual()
| |
手写比较函数
其实比较两个 Slice 的思路也简单:
- 先看看长度是否相等;
- 再看看是不是都为 nil 或 都不为 nil,是就 true,否就下一步(都为 nil 也是相等);
- 遍历随便哪一个,在遍历中两两比较,一旦不等就返回 false(如果是用在安全方面要预防计时攻击)
| |
在遍历之前还可以加入 BCE 优化,不过第一步比较长度时,编译器已经获取了 a 和 b 的长度了,在遍历时应该不会再次检查边界了。
性能陷阱
问题
golang 具有垃圾回收功能,而一个切片的底层数组,有可能被多个切片引用(即有多个 Slice 指向同一个底层数组),例如 [:] re-slice 就是对底层数组的再一次引用。
这样的机制就有可能带来一个问题:
有一个结构体切片 a 有100 个元素,每个结构体的大小是 1 MB,也就是 a 的大小是 100 MB;
然后另一个切片 b 引用了 切片 a 最后两个元素,即
b := a[len(a)-2:]。当 a 使用完后 GC 是没法回收这个 100 MB 的底层数组的,因为还有 b 在引用着。于是就会出现这种 用到只有 2 MB,但却无法回收剩下 98 MB 的空间。这就是我想说的性能陷阱。
| |
解决方法
比较推荐的做法是,采用 copy() 的方法替代 re-slice,因为 copy(b, a) 后 a 和 b 引用的不是同一个底层数组。这样 a 使用完以后,底层数组那 100 MB 的空间也能被 GC 回收。
| |
BCE 优化
边界检查
总结
- 每个 Slice 都指向一个底层数组
- 每个 Slice 都保存了当前 Slice 的长度、底层数组的可用容量
- 因为 Slice 本身是结构体,带有
len和cap字段,所以计算长度和容量都是O(1) - 因为 Slice 本身是结构体,所以通过函数传递时不会拷贝整个切片,属于引用传递
- 因为 Slice 本身是结构体,其中 array 字段为指针类型,所以在函数内对 Slice 的修改会影响到外部。
- 使用 append() 追加元素时有可能触发扩容,扩容后将生成新的切片
- 使用 copy() 复制 Slice 时,目的 Slice 原有的内容会被覆盖
- 创建切片时尽可能根据实际需要预分配容量,尽量避免追加过程中扩容操作,有利于提升性能
- 拷贝时需要判断实际拷贝的个数
- 谨慎使用多个切片操作同一个数组,以防读写冲突